
This an introductory post about PostGIS Baselayers, which is a web application I've been working on that downloads and imports popular vector datasets (Natural Earth, GADM, Geonames, etc) into a PostGIS spatial database with the click of a button. It comes bundled with a Docker environment and a PostGIS database container to get up and running quickly.
This post will explain the how and why in some more detail.
Keep an eye on the repository on Github for any news and future updates: https://github.com/kokoalberti/postgis-baselayers. If you'd like to request a particular dataset to be included in future releases, please create an issue or contact me via @kokoalberti and I'll see if I can look into it.
Why
Accessibility of spatial datasets is something that's been a bit of a lingering annoyance to me for a long time now. It always takes a lot of time to find data on a particular theme, download it from some silly data portal, wrestle with (sometimes proprietary or ancient) data formats, figure out what is what in a dataset, coerce it into some sort of unified database (or a bunch of random Shapefiles in a directory if you're in a hurry), and then finally you can start out with what you wanted to do in the first place: run spatial queries across a bunch different datasets for analysis or visualization purposes. There must be some better way of going about this.
A few months ago, in a moment of inspiration, I started working on a webapp to automate this process and threw a very rudimentary version of PostGIS Baselayers up on my Twitter account:
It was a rather shabby looking app and I was not really expecting anything, but it nevertheless got some positive feedback, indicating that the problem it solves is something that people may be interested in.
After this I spent some time adding additional datasets and improving the web application and underlying install scripts to a point where I feel that it's working quite well and I'd like to share it more widely. So here we are.
Getting started
Getting up and running with the included Docker environment is probably the fastest. Clone the repository using git clone https://github.com/kokoalberti/postgis-baselayers and use Docker Compose to build and start the necessary containers:
$ git clone https://github.com/kokoalberti/postgis-baselayers (...) $ cd postgis-baselayers $ docker-compose build $ docker-compose up
Docker will now start one container with an empty PostGIS database, and another one which uses supervisord to run the Flask web application and a Huey work queue with installation tasks in the background.
You should now be able to visit the application in your browser at http://localhost:8003:
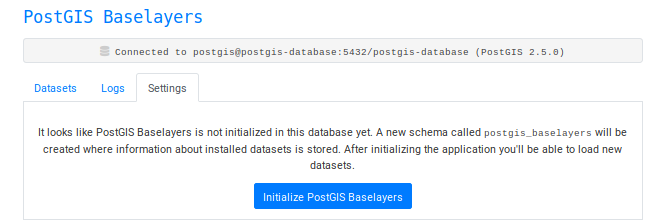
Because the database is still empty we'll need to create a new schema called postgis_baselayers where some metadata about our layers (which ones are installed, etc) is stored. After initializing the database we can select datasets to install:
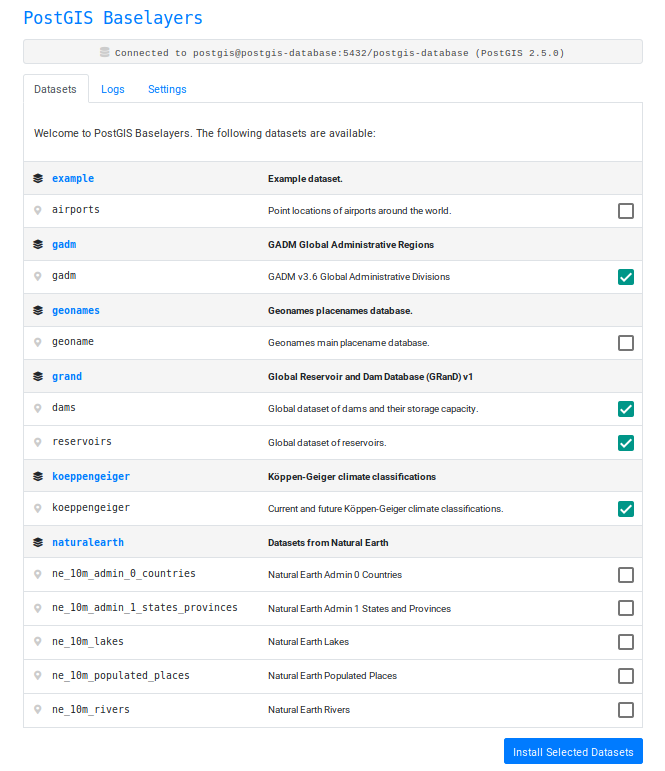
The tasks for which are then queued, and processing of the queue is started:
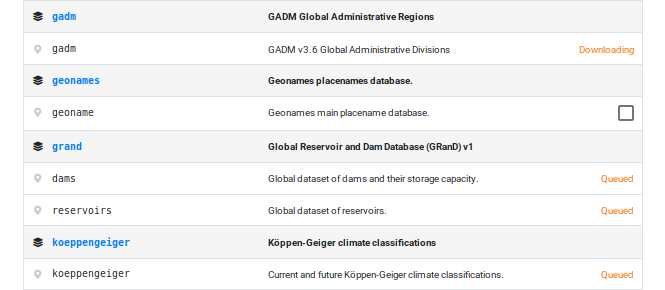
And after a few minutes the datasets are installed:
Each dataset is installed into its own schema, the name of the schema following the name of the dataset.
Accessing data
The PostGIS database started with the default docker-compose up command is accessible with the following credentials:
Hostname: localhost Port: 35432 Database name: postgis-database Username/password: postgis
It runs on a different port (35432 instead of 5432) to avoid conflicts with any other databases running on the Docker host.
PSQL
You can use the psql command line tool to connect to the database directly and run queries:
$ psql postgresql://postgis:postgis@localhost:35432/postgis-database psql (11.3 (Ubuntu 11.3-1.pgdg18.04+1), server 10.5 (Debian 10.5-1.pgdg90+1)) Type "help" for help. postgis-database=# select postgis_version(); postgis_version --------------------------------------- 2.5 USE_GEOS=1 USE_PROJ=1 USE_STATS=1 (1 row) postgis-database=#
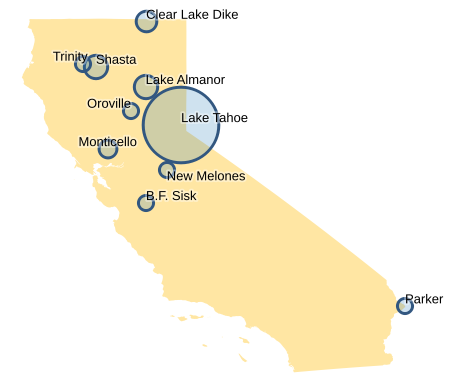
Now we can run queries across different datasets, for example to make a list of the dams with the largest reservoirs in the state of California by combining the GADM and GRanD datasets:
SELECT grand.dams.geom AS geom, grand.dams.dam_name AS dam_name, grand.dams.area_skm AS reservoir_area FROM grand.dams, gadm.level1 WHERE gadm.level1.name_1 = 'California' AND ST_Intersects(grand.dams.geom, gadm.level1.geom) ORDER BY reservoir_area DESC LIMIT 10;
Which returns something like:
geom | dam_name | reservoir_area ----------------------------------------------------+-----------------+---------------- 0101000020E61000007FA4703D0A095EC0FA66039D36944340 | Lake Tahoe | 495.6 0101000020E610000049713D0AD7455EC09F11AE47E1164440 | Lake Almanor | 102.9 0101000020E6100000B2111111119B5EC0F266039D365C4440 | Shasta | 102.4 0101000020E61000007CA4703D0A455EC0DDF2285C8FF64440 | Clear Lake Dike | 91.5 0101000020E610000057824E1BE8865EC00CDBDDDDDD414340 | Monticello | 66.3 0101000020E61000003415AE47E1885CC0388925BF58264140 | Parker | 60.8 0101000020E610000033602CF9C5B05EC09C11AE47E1664440 | Trinity | 56.3 0101000020E6100000C0E8B4814E455EC01B154B7EB1884240 | B.F. Sisk | 48.8 0101000020E610000059824E1BE85E5EC0097814AE47C54340 | Oroville | 45.6 0101000020E6100000062DF9C592215EC057BC58F28BF94240 | New Melones | 43.2 (10 rows)
GDAL/OGR
To turn the results of this SQL query into any compatible vector format, you can use the ogr2ogr utility. If we store the above query in a query.sql textfile, we can use the following command to turn easily turn the results into a GeoPackage file:
$ ogr2ogr -f "GPKG" \ output.gpkg \ PG:"dbname=postgis-database host=localhost port=35432 user=postgis password=postgis" \ -sql @query.sql
Should give you GeoPackage in output.gpkg containing points with a dam_name and reservoir_area properties, which we can use with some other GADM data to make a fancy map in QGIS:
QGIS
In QGIS you can create a new PostGIS connection to access the data directly:
I won't go into details about accessing data in a PostGIS database from QGIS, but I'm sure there are some tutorials out there that explain this quite well.
Current Datasets
Currently a selection of the following datasets are included in PostGIS Baselayers:
As well as an example dataset that can help you get started if you're interested in adding other datasets yourself.
Future Plans
Improving some of the following issues would make the app more useful for a bigger audience, so I'd like to work on that if I find some time in the coming months:
- Adding more datasets! It would be awesome if there was a decent collection of datasets covering all sorts of themes right at your fingertips. If you'd like to request a dataset to include, create an issue in the issue tracker on Github.
- A better upgrade path for when new datasets are added. It would be nice if the application would give a notification when new datasets are available, or even just update the index automatically and let you install any new datasets that you're interested in.
- Better documentation and query examples. Especially when you first encounter a new dataset it can take a bit of time to figure out what's actually in there, and how the data is structured and stored. An extensive set of examples for each dataset reduces this learning curve, as well as provide lots of code examples for users that are just getting started with PostGIS and spatial queries.
- Various improvements to the web application itself. Things like configuring the database to connect to from the browser rather than using an
.envfile, switching between multiple databases, maybe some better management of the tasks running in the background, these sort of things.
If you're interested, keep an eye on the repository on Github for any news and future updates: https://github.com/kokoalberti/postgis-baselayers.
Thanks for reading! Get in touch via @kokoalberti for any questions or comments. I also post new articles there when they are first published.